【Python】 機械学習の前処理その4 テストデータを分割しロバスト性を上げる ホールドアウト法の使い方
- 2021.08.09
- Python
- scikit-learn, 前処理, 機械学習

まえがき
機械学習の前処理第4回です。以前の投稿はこちらから。
【Python】機械学習の前処理正規化 (Normalization) 標準化 (Standardization) 2つの違いは?
【Python】 機械学習の前処理その2 統計とNaNの確認 describe と sum
【Python】機械学習の前処理その3 NaNを除外 、線形・多項式補間する方法!
機械学習アルゴリズムを評価する基準の一つにロバスト性(頑健性)という指標があります。ロバスト性とは、外れ値や、飛び値等がデータに含まれる場合や、運用時にテストデータと異なる傾向が出た場合にも、間違った予測をしにくい性質のことです。例えば、外れ値の影響を受けにくいアルゴリズムは、「外れ値に対するロバスト性が高い」等と表現します。
本記事では、特に、データの傾向変化に対するロバスト性を向上する方法として、ホールドアウト法を使ったテスト方法をご紹介したいと思います。
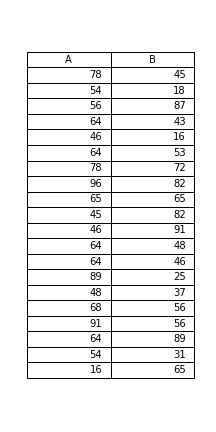
テストには以下のデータを使います。
ホールドアウト法とは
ホールドアウト法とは、テストデータを学習用データと評価用データに分割して評価する方法のことです。学習用データのみを使って学習を行った後、評価用データで実際の運用時と同じ条件で予測を行い、その正解率を評価します。こうすることで、テストデータでは好成績でも、実運用時は予測が合わなくなるという、過学習と呼ばれる現象を避けることができます。以下がホールドアウト法のイメージ図です。
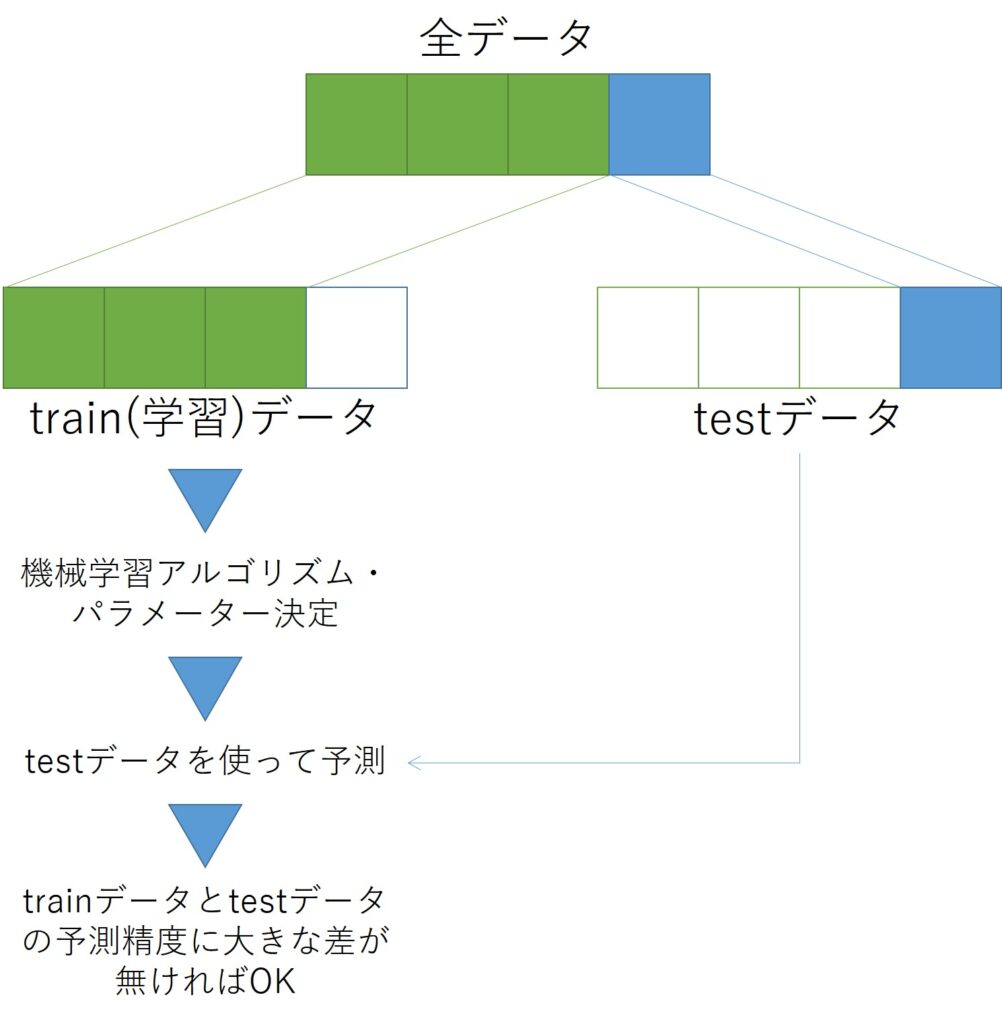
上記イメージ図は最も単純な分割の例です。実際には分割の方法はいくつかあり、正しく使いこなすことで、上記のような単純な分割よりも更に高精度なテストを行うことができます。
scikit-learn (sklearn) を使ったホールドアウト法
Pythonでホールドアウト法を行う場合、 scikit-learn のtrain_test_splitを使用します。詳細は以下の公式リファレンスをご覧ください。
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html?highlight=train_test#sklearn.model_selection.train_test_split
まずは、上記の図で説明した一番単純な分割を行うソースを示します。
from sklearn.model_selection import train_test_split
train, test = train_test_split(df,
test_size = 0.3,
shuffle = False,
random_state = 0,)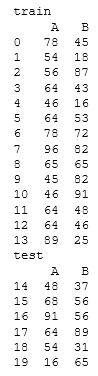
さて、一番単純な分割という割に、引数を4つも指定していてややこしいと思われたのではないでしょうか。まず、「df」は必須項目で、分割する対象のDataFrameです。Arrayでも分割できます。次に「test_size」はテストデータの割合で、デフォルトは0.25となっています。残りの二つは少しわかりにくいので少し詳しく解説します。
まず、「shuffle」はデフォルトではTrueとなっています。 「shuffle」 がTrueの場合、データ分割の際、以下の図のように、インデックスをランダムに並べ替えます。
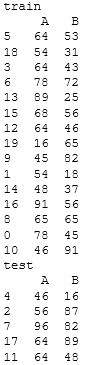
ランダムに並べ替えを行うことで、より一層テストデータの傾向に左右されない学習ができるメリットがあります。反面、時系列データなど、順番に意味のあるデータの場合は、順番の持つ情報を破壊してしまうので不適です。データの特性を理解したうえで使用することが大切です。
最後に、「random_state」はデフォルトではNoneとなっています。この状態で 「shuffle」 がTrueの場合、実行するたびに並べ替えのパターンが変化します。
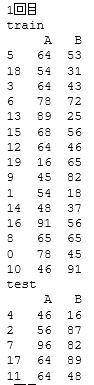
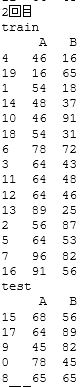
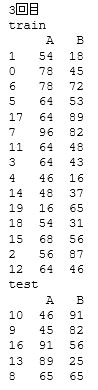
並べ替えをしながら複数回のテストを行い、全てで同程度の精度が出せれば、データ傾向に対するロバスト性はかなり高いと言えるでしょう。
まとめ
データを分割して、機械学習のロバスト性を向上するテスト方法、ホールドアウト法についてご紹介しました。記事内でも書いたことの繰り返しになりますが、データの並び替えはデータの順序が持つ情報を破壊してしまいます。今回ご紹介した、 scikit-learn のtrain_test_splitはデフォルトで並び替えを行う設定になっているので、利用する際はデータの性質をよく確認して、必要に応じてshuffle = Falseを忘れないようにしてください。
-
前の記事

【Python】 DataFrameを表として画像ファイルに出力する方法 2021.08.08
-
次の記事

【MQL5】 MT5のEA作成の勉強 その1 EAの1番簡単な作り方 + 処理順の確認 2021.08.10