【Python】iloc , iat の速度比較。DataFrameの選択に使うべきは?

まえがき
iloc , iat はいずれもPandasのDataFrameを選択するための関数です。ilocについては、以前別の投稿で触れましたが、いずれもDataFrameの行番号、列番号を指定して選択する関数です。(列名を選択したい場合にはloc , atを使います。)
PandasのDataFrameをJupyterNoteBookに表示する方法4選!列数編
iloc , iatの使い方の違いと実行速度の比較をして、どちらを使うべきかを調べてみたいと思います。
公式リファレンスは以下をご参照ください。
iloc
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.iloc.html#pandas.DataFrame.iloc
iat
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.iat.html#pandas.DataFrame.iat
ilocの使い方
ilocを使う際は「iloc[行番号,列番号]」というように、行番号→列番号の順に引数を指定します。引数の指定方法は主に以下の4つです。なお、番号は0始まりで表記し、負の数は最後から遡って指定することを意味します(例:-1=最後から一行目)。以下に使用例を示します。
df = pd.DataFrame([["a0","b0","c0"], ["a1","b1","c1"], ["a2","b2","c2"]],
columns=['A', 'B', 'C'])
display(df)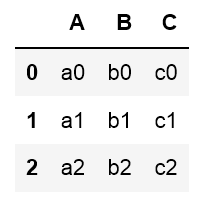
- 行番号、列番号を指定
行番号と列番号を直接入力します。配列を入力すると複数の行、列を同時に指定できます。
#1行目を抜き出し
df.iloc[0]
#1行目の1列目を抜き出し
df.iloc[0,0]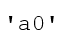
#1,2行目の1,2列目を抜き出し
df.iloc[[0,1],[0,1]]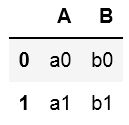
- 行番号と列番号の範囲を指定
開始位置と終了位置の間に”:“を挟むことで、範囲を指定します。
#1~2行目の1~3列目を抜き出し ※終了位置に指定した番号は含まれない
df.iloc[0:2,0:3]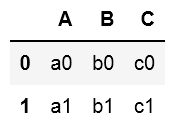
#3行目より前の行の1列目より後の列を抜き出し
df.iloc[:2,1:]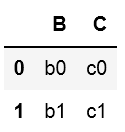
#最終行から2行上~最終行の一列目より後~最終列
df.iloc[[0,1],[0,1]]- 全範囲を指定
“:”を単独で入力すると、全範囲選択となります。列番号は空欄でも全選択とみなされます。
#全範囲選択 ※df.iloc[,]とdf.iloc[ ,:]はエラー
df.iloc[:,:]
#または
df.iloc[:,]- 条件を満たす列を指定
ラムダ式形式で条件を入力すると、条件に合致した列の未抽出されます。
#1行目以後かつ2行目以前の行を抜き出し
df.iloc[lambda x: (x.index >= 0) & (x.index <= 1)]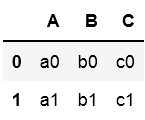
iatの使い方
iatの使い方はほぼilocと同じです。しかし、 引数として数値しか入力できず、行と列を両方入力する必要があるという制限があります。配列や”:“による複数指定ができないため、選択可能範囲は常に一つのセルとなります。
#1行目の1列目を抜き出し
df.iat[0,0]ilocとiatの速度比較
さて、現状ではiatはilocの完全下位互換で、使い道がないと言わざるを得ません。しかし、本当にそうなら存在する意味がありませんし、Web上では「iatの方が高速」という記事も見受けられます(公式リファレンスに速度に関する記載はありませんでしたが)。そこで、実際に、ilocとiatの速度を比較してみたいと思います。
テストデータとして、以下の10000行×10列のDataFrameを用います。これを、同じサイズの0のみが格納されたDataFrameにコピーする処理の速度を調べます。同じ処理を50回連続して行い、その平均速度を比較します。
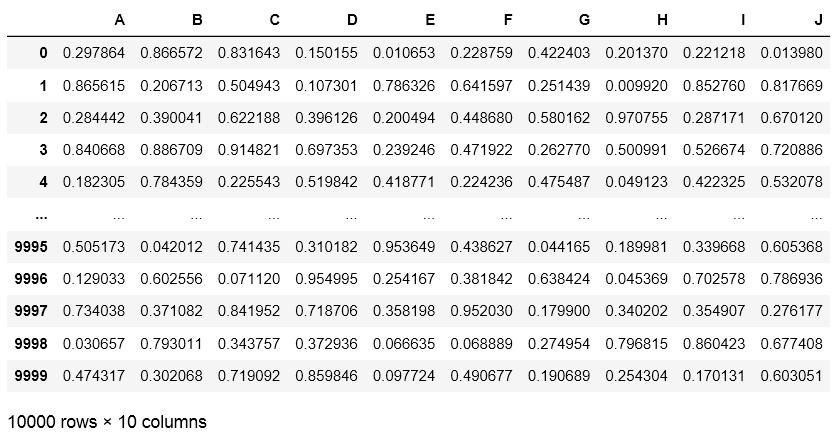
まずは、一セルずつコピーする処理にかかる時間を比べてみたところ、以下のようになりました。測定に使ったソースも下に示します。
- iloc
所要時間 : 40.566 [s] - iat
所要時間 : 40.025 [s]
#ilocの所要時間
mea=[]
for s in range(1,50):
df_iloc2=df
for i in ["A","B","C","D","E","F","G","H","I","J"]:
df_iloc2[i] = 0
start = time.time()
for i in ["A","B","C","D","E","F","G","H","I","J"]:
for j in range(0,9999):
df_iloc2[i][j] = df[i].iloc[j]
calculation_time = time.time() - start
print ("calculation_time:{0}".format(calculation_time) + "[s]")
mea.append(calculation_time)
print("average")
print ("calculation_time:{0}".format(mean(mea)) + "[s]")#iatの所要時間
mea=[]
for s in range(1,50):
df_iat=df
for i in ["A","B","C","D","E","F","G","H","I","J"]:
df_iat[i] = 0
start = time.time()
for i in ["A","B","C","D","E","F","G","H","I","J"]:
for j in range(0,9999):
df_iat[i][j] = df[i].iat[j]
calculation_time = time.time() - start
print ("calculation_time:{0}".format(calculation_time) + "[s]")
mea.append(calculation_time)
print("average")
print ("calculation_time:{0}".format(mean(mea)) + "[s]")・・・ほぼ速度は変わりません。もしかしたら、列数が多いと差がつくのかもしれないと思い、10行×1000列のデータでも同じ実験を行いましたが、結果は以下のようになりました。
- iloc
所要時間 : 15.450 [s] - iat
所要時間 : 15.269 [s]
やはり全く差がありません。しかも、ilocだけが使用できる”:“による一括選択を行うと、始めの10000行×10列のテストデータの計算時間は以下のようになりました。
- iloc
所要時間 : 0.002 [s] - iat
計算不可
#iloc列ごと
mea=[]
for s in range(1,50):
df_iloc=df
for i in ["A","B","C","D","E","F","G","H","I","J"]:
df_iloc[i] = 0
start = time.time()
for i in ["A","B","C","D","E","F","G","H","I","J"]:
df_iloc[i] = df[i].iloc[:].values
calculation_time = time.time() - start
print ("calculation_time:{0}".format(calculation_time) + "[s]")
mea.append(calculation_time)
print("average")
print ("calculation_time:{0}".format(mean(mea)) + "[s]")圧倒的に早いです。一般的にFor文によるループは極力避けるのが、速度を上げるための第一歩です。今回も、行数分のループが無くなったことで速度が上がったようです。
まとめ
少なくとも、今回の調査においては、iatを使うメリットを見出すことはできませんでした。単に互換性を保つためだけに残されるレガシーな機能なのか、私の見つけられなかった利点が隠されているのかはわかりませんが、とりあえずilocを使うようにすべきでしょう。
-
前の記事

【MQL5】 MT5のEA作成の勉強 その25 Gogo Jungle(ゴゴジャン)に、インジケータを登録する方法 2021.10.03
-
次の記事
【MQL5】 MT5のEA作成 その2 リピート型EA試作 2021.10.17