JupyterNoteBookで、Pandas.DataFrameのindexを1つずらす。

JupyterNoteBookでPythonのライブラリ、PandasのDataFrameの列を、indexをずらして複製する方法を紹介します。
まえがき
時間データを扱うとき、PandasのDataFrameにindexをずらした列を追加したい場合が結構あります。
なぜなら、indexをずらした列はある時刻における、未来、もしくは過去の値として使用することができるため、機械学習で未来予測を行うときの入力データとして有用だからです。
しかし、それを作ろうとすると、DataFrameはExcelの様にセルを削除できない上に、列を追加すると勝手にindexを合わせてしまうので、工夫が必要になります。本記事では、indexをずらした列を追加する方法を紹介します。
DataFrameの詳しい使い方は以下の公式サイトを確認してください。
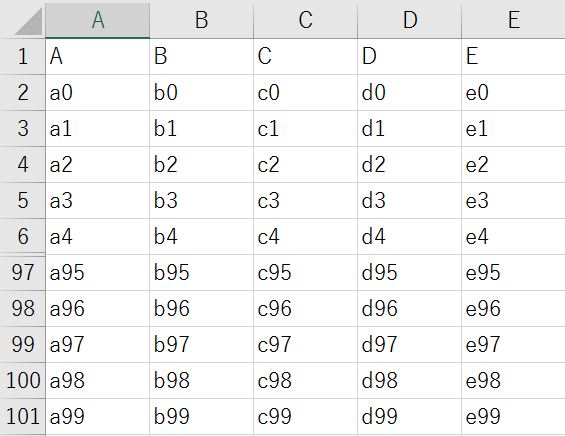
前回までの記事と同じく、今後の例では以下のcsvデータを使用します。
1行目はヘッダーで、2行目~101行目までの100行×5列のデータです。
csvデータを読み込む方法については以下の記事を参照してください。
https://tedukapm.tech/?p=12
環境はPython3.8、JupyterNoteBook6.3.0です。
やりかた
以下の方法で、A列を1行ずつずらして、Shift列を作ることができます。
shift_df = pd.DataFrame({'Shift0':df['A'].iloc[0:-10]})
for i in range(0,10):
shift_df['Shift'+ str(i)] = df['A'].iloc[i:-(10-i)].values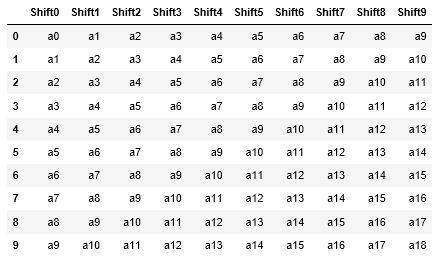
説明
上のコードでやっていることを説明します。
まず、1行目では”Shift_df“というDataFrameを新規作成しています。この時、右辺でShift_dfの中身を作っているのですが、ここでは、”Shift0“という名前の列を作り、その中身を、dfのA列の後ろから10行を抜き取ったものにしています。
次に、2行目~3行目で、”Shifti”という名前の列をShift_dfに追加して行きます。その中身はdfのA列の前からi行と後ろから10-i行を抜き取ったものです。ずらすだけなら、前から抜き取るだけでよいのですが、DataFrameの仕様で、全ての列が同じ行数でなければならないので、行数を合わせるために後ろからも抜き取っています。
まとめ
JupyterNoteBookでPythonのライブラリ、PandasのDataFrameのカラムを、indexをずらして複製する方法を紹介しました。
-
前の記事

PandasのDataFrameをJupyterNoteBookに表示する方法4選!列数編 2021.07.18
-
次の記事

【Excel VBA】ループ処理の中断ボタンを作る。マルチスレッドの1歩前に試すべき方法。 2021.07.20