Pandasのread_csvでFXの過去データをDataFrame化する為の4ステップ

Pythonのライブラリ、Pandasのread_csvを使って、FXの過去データ(ヒストリカルデータ)をDataFrameとして取り込む方法を4ステップで紹介します。
まえがき
FXの過去データのcsvファイルをPandasのread_csvを使って、日付型indexを持つDataFrame(df)として読み込みます。
read_csvの基本的な使い方は以下のページで解説しています。
read_csvの詳しい使い方は以下の公式サイトを確認してください。
https://pandas.pydata.org/docs/reference/api/pandas.read_csv.html?highlight=read_csv
実行環境はPython3.8、JupyterNoteBook6.3.0です。FXの過去データはFXTF(ゴールデンウェイ・ジャパン)さんが口座を開設した人限定で無料配布している1分足データを15分足に加工して使用します。過去データの入手方法や加工方法は後日解説しますが、以下のようなデータを使います。
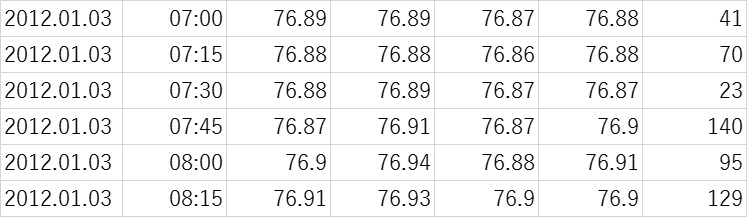
環境はPython3.8、JupyterNoteBook6.3.0です。
やりかた
結論から言いますと、以下のコードで、filePathで指定したFXの過去データを読み込むことができます。読み込んだ後、indexのDateTime型への変換と余分な列の削除を行っていますが、それぞれのコードについては以下で解説してゆきます。
df = pd.read_csv(filePath,
names = ['Date','Time','Open','High','Low','Close','Volume'])
df['DateTime'] = pd.to_datetime(df['Date'] +" "+ df['Time'], format='%Y.%m.%d %H:%M')
df.set_index('DateTime',inplace = True)
df.drop({'Date','Time'},axis = 1,inplace = True)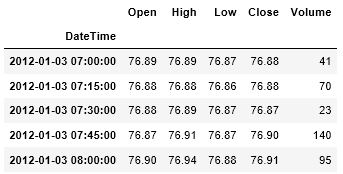
csvファイル読み込み
df = pd.read_csv(filePath,
names = ['Date','Time','Open','High','Low','Close','Volume']) filePathでcsvファイルのパスを指定しています。
namesにで指定している配列はFX過去データの列につける名前です。
DataFrameへの列追加
df['DateTime'] = pd.to_datetime(df['Date'] +" "+ df['Time'], format='%Y.%m.%d %H:%M') 左辺にはdfに含まれない列名DateTimeを指定しています。
DataFrameの仕様で、存在しない列名=新規作成という扱いになるので、ここでは新規にDateTime列を追加しているというわけです。
一方、右辺はpd.to_datetimeを使用しています。これは第一引数の文字列をDateTime型に変換するAPIで、第二引数ではフォーマットを指定します。
今回の例では、Date列とTime列を間にスペースを入れて結合し、その文字列をDateTime型に変換するという処理になります。
なお、フォーマットの指定方法は以下の公式サイトを確認してください。
https://docs.python.org/3/library/datetime.html#strftime-and-strptime-behavior
indexを指定
df.set_index('DateTime',inplace = True) 先ほど新規に追加したDateTime列を、set_indexを使ってindexに指定します。
第二引数のinplace = Trueというのは、この変更をdfに適用するということを示しています。これを入れておかないとdfが変更されずに首をかしげることになるので注意しましょう。
余分な列を削除
df.drop({'Date','Time'},axis = 1,inplace = True)最後にdf.dropを使って、不要になったDate列とTime列を削除します。
まとめ
FXの過去データのcsvファイルをPandasのread_csvを使って、日付型indexを持つDataFrame(df)として読み込みました。次回・・・かどうかは分かりませんが、今後も勉強してまた続きを書きたいと思います。
-
前の記事

Pandasのread_csv使い方!~multiindex、datetime型index 2021.07.14
-
次の記事
PandasのDataFrameをJupyterNoteBook上に表示する方法6選! 2021.07.17